저번 시간 분류 모델 개념 정리 내용을 바탕으로
[빅데이터분석기사필기] 필기 3과목 메타코드 강의 | 분류모델 - 로지스틱휘귀(Logistic Regression)와
저번 시간에는 회귀분서에 대한 개념과 문제풀이를 진행했는데요 [메타코드M 빅데이터 분석 기사 필기] 3과목 회귀분석 관련 문제 풀이 및 정리 회귀분석과 다중회귀분석에 이어서 회귀분석 관
toonovel.tistory.com
[빅데이터분석기사] 필기 3과목 메타코드 강의 | 분류모델 - 의사결정나무, 앙상블모형, K-NN 개념
저번 분류모델인 SVM과 로지스틱회귀분석 개념에 이어서 [빅데이터분석기사필기] 필기 3과목 메타코드 강의 | 분류모델 - 로지스틱휘귀(Logistic Regression)와 저번 시간에는 회귀분서에 대한 개념과
toonovel.tistory.com
이번 강의에서는 지도학습 중 분류 모델에 관련된 문제를 풀어볼 예정입니다
https://mcode.co.kr/mypage/lecture_view?wm_id=993&lecture_id=5&lecture_sub=18&lecture_num=2
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
문제풀이
Q1 로지스틱 회귀분석에 대한 설명으로 틀린 것은?
보기
1. Y값은 범주형 변수이다
2. 회귀/분류 모두에 사용이 가능한 분석 방법이다
3. 특정 클래스에 속할 확률을 구하여 2가지 범주 중 하나로 분류한다
4. 시그모이드 함수를 사용한다
- 풀이
종속변수가 범주형인경우 ,이진분류(0 아니면 1로 분류)
시그모이드 함수(S자 곡선) : Y가 1일 확률값을 구해준다(0~1사이 값)
임계값은 보통 p=0.5
확률값이 0.5보다 크면 1로 분류 하고 그렇지 않으면 0으로 분류
Q2 서포트벡터에 대한 설명으르 틀린 것은?
보기
1. 지도학습 모델로 회귀/분류 모두 사용이 가능하다
2. 마진을 최대로 하는 초평면을 구한다
3. 초매개변수인 C값을 증가시키면 과소적합이 발생할 가능성이 있다
4. 선형/비선형 데이터도 분류가 가능하다
- 풀이
1) 데이터 세트를 분할하기 위한 최상의 초평면을 구함
2) 특징
-성능이 좋으나 하이퍼파라미터(초매개변수) 영향을 많이 받는다
-계산량이 많아서 시간 소요
3) 커널 : 비선형 데이터 분류시 커널 함수를 통해 다른 차원으로 맵핑하여 해결
4) 하이퍼파라미터 C값 증가 = 하드마진(타이트하게) = 성능이 높아짐 = 과적합 위험
- 정답 : 3번
Q3 의사결정나무에 대한 설명으로 틀린 것은?
보기
1. 지도학습으로 회귀/분류 모두 사용이 가능하다
2. 이상치에 영향을 크게 받지 않고 일반적으로 성능이 좋다
3. 의사결정나무 시각화시 직관적으로 이해가 쉽다
4. 분류 모델로 사용할 때 분류기준은 카이제곱 통계량, 지니지수, 엔트로피 지수 등이 있다
- 풀이
1) 회귀일때 분리기준: 분산분석 F-통계량 p값, 분산의 감소량
2) 분류일때 분리기준 : 카이제곱 통계랑 p값, 지니지수, 엔트로피 지수
* 대표적인 DT알고리즘 CART 특징 : 지니지수, 분산의 감소량 사용
3) 장단점
- 장점: 의사결정나무 시각화시 직관적 이해 쉬움, 비선형 분석가능, 비모수적(가정 불필요)
-단점: 이상치에 영향을 크게 받음, 성능이 그리 좋지 않음
- 정답 : 2번
Q4 앙상블 모형에 대한 설명으로 틀린 것은?
보기
1. 여러개의 붓스트랩 자료를 생성하고 각 자료를 모형화한 후 결합하여 최종 결과를 산출하는 것을 배깅이라고 한다
2. 약한 분류기를 여러개 모아 강한 분류기를 생성하는 방법을 부스팅이라고 한다
3. 약한 학습기들을 생성하고 이를 선형 결합해 최종 학습기를 만드는 방법을 랜덤포레스트라고 한다
4. 전체 변수 중에 일부 변수를 선택하여 의사결정나무를 무작위로 생성한 후 최종 결과 값을 산출해내는 모형을 배깅이라 한다
- 풀이
1) 배깅
붓스트랩으로 데이터셋 생성 -> 각 데이터셋마다 모델링 -> 투표해서 최종 값 결정
*붓스트랩: 단순 랜덤 복원추출
2) 부스팅
-예측력이 약한 모델에서 오류에 가중치를 줘서 더 좋은 모델로 발전시켜나감
-모델링 -> 오분류데이터에 가중치를 부여 -> 모델링 -> 오분류 데이터에 가중치 부여 순
-종류 : GBM, XGBoost, adaboost
3)랜덤포레스트(배깅 + 변수 선택)
-다수의 의사결정나무를 랜덤으로 만들어 그 결과값을 투표하여 최종 값 결정
(회귀: 평균, 분류: 투표)
-노이즈에 민감하지 않음
-배깅보다 더 많은 무작위성을 부여, 하나는 약하지만 다수는 강하다는 원리
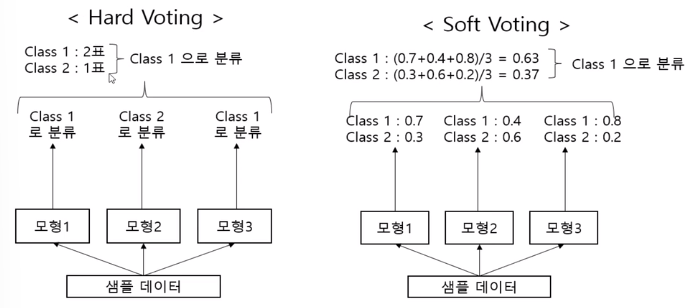
Hard voting / Soft voting
'Extracurricular activities > [메타코드] 빅데이터분석기사' 카테고리의 다른 글
| [빅데이터분석기사] 필기 3과목 메타코드 강의 | #10 군집분석 개념 정리 및 문제풀이 (0) | 2024.03.25 |
|---|---|
| [빅데이터분석기사] 필기 3과목 메타코드 강의 | #9 인공신경망/딥러닝 함수 개념 정리 및 문제풀이 (0) | 2024.03.24 |
| [빅데이터분석기사] 필기 3과목 메타코드 강의 | #7 분류모델 - 의사결정나무, 앙상블모형, K-NN 개념 정리 및 요약 (0) | 2024.02.20 |
| [빅데이터분석기사] 필기 3과목 메타코드 강의 | #6 분류모델 - 로지스틱휘귀(Logistic Regression)와 SVM 개념 정리 (0) | 2024.02.19 |
| [빅데이터분석기사] 필기 3과목 메타코드 강의 | #5 회귀분석 문제풀이 및 정리 (1) | 2024.02.18 |



