이번에는 데이터를 통합하고 인덱싱 필터링 정렬을 진행해보겠다
계속 참고해온 데이터는 kaggle의 "web page phishing detection dataset" 인데
https://www.kaggle.com/datasets/shashwatwork/web-page-phishing-detection-dataset
Web page Phishing Detection Dataset
Detect Phishing in Web Pages
www.kaggle.com
그룹화하기엔 맞는 데이터가 아니라서 seaborn의 iris 데이터도 활용해서 연습해보겠다
iris 데이터 불러오기
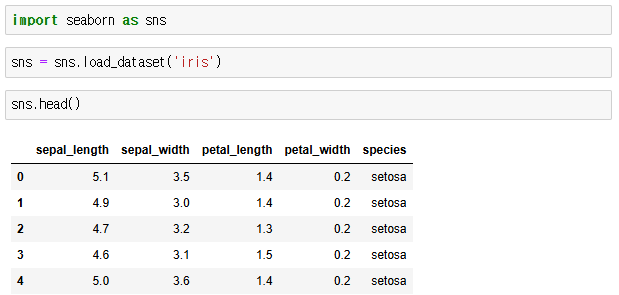
groupby()
그룹화

문제가 species를 기준으로 중앙값/ 평균의 그룹을 구하라~ 이런식이면
sns.groupby('species').mean()
sns.groupby('species').median()
groupby 뒤에 함수를 적어주면 된다
데이터 인덱싱
행 / 열 익덱싱 df.loc[행, 열]


열만 인덱싱할 경우 행에는 ' : ' 넣기 df.loc[:,'열명']

행 여러개 인덱싱 1:4 범위 설정 해주고
열 여러개 인덱싱 안에 [ ] 괄호 한번 더해서 ['status','ip'] 로 작성

df 데이터의 앞/뒤 에서 n행 인덱싱
앞에서 n행 인덱싱 : head()
뒤에서 n행 인덱싱 : tail()
열 추가 / 제거
열 추가 하는데 해당 기존 데이터를 망칠 수 없어서
df2 = df.copy() 로 새로운 데이터프레임 df2로 진행
1) 열 추가

df['변수명'] 작성후 새로운 값에 추가 -> 그럼 추가한 해당 변수만 나옴

새로운 열을 추가 하고 싶을 때 열 명칭도 같이 지정해줘야함
끝부분 표를 보면 new 라는 열이 새로 생긴걸 볼 수 있음
2) 열 제거
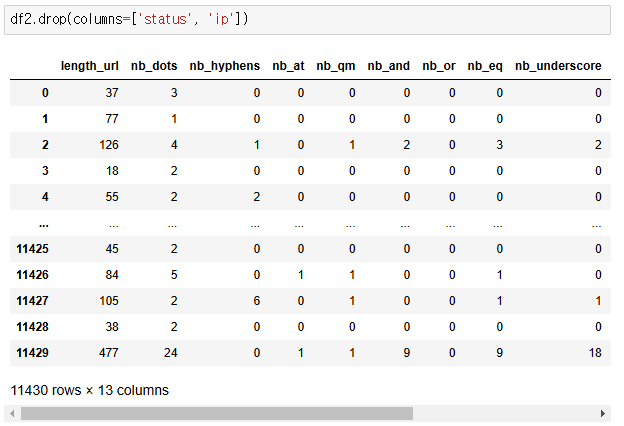
df.drop(columns = ['변수명1', '변수명2' ,,,]
데이터 필터링
파이썬에서 같다는 '==' 임 (까먹지 말기)

=> nb_dots 가 1인 값은 True 아니면 False
=> 굳이 count에 적용안해도 안에 조건만 작성해도 동일하게 나옴

=> 정확한 개수를 세고 싶다면 len 활용 (행의 개수 세줌)
=> df[] 를 씌우지 않고 그대로 count사용하면 전체열 개수 출력

=> df[]를 쓰우면 조건에 맞는 행의 개수만 출력함
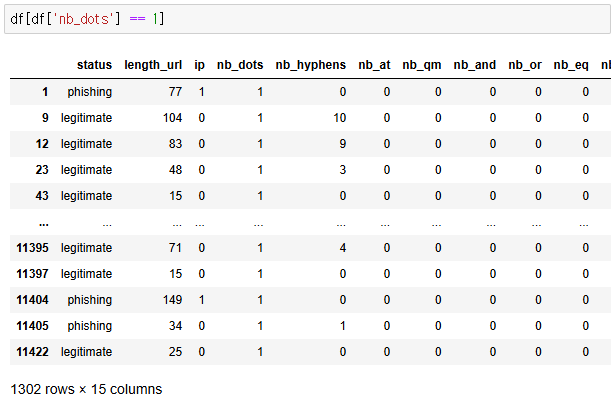
=> df[조건] : df에서 조건에 해당하는 값들만 데이터프레임 형태로 출력
=> nb_dots 가 1인 값만 df를 출력
** 조건이 2개인 경우

새로운 조건 count2 생성

| (or) 또는
& (and) 그리고
데이터 정렬
내림차순 정렬 과 오름차순 정렬
df.sort_values('변수명' , ascending= True 또는 False)
** values 주의 s 있음

=> False 일때 내림차순(큰 수에서 작은 수) / Ture 일 때 오름차순
조건문
np.where 이라는 조건문 있음 / if ~ else문과 동일함

'Study > 빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 실기 1과목 데이터 표준화, min-max scaling,데이터 합치기 (0) | 2024.11.15 |
|---|---|
| 빅데이터분석기사 실기 1과목 실기 데이터 결측치, 이상치, 중복값 처리 (0) | 2024.11.14 |
| 빅데이터분석기사 실기 1과목 데이터산포도 분산, 표준편차, iqr, 절댓값 , 최대최소, 합계 (2) | 2024.11.12 |
| 빅데이터분석기사 실기 2과목 분류모델 데이터 전처리 및 모델링 진행 (3) | 2024.11.09 |
| 빅데이터분석기사 실기 1과목 head, info, describe, shape, dtypes, astype, 최소값/최대값/최빈값, 변수 개수 구하기 정리 캐글 데이터 활용 (0) | 2024.11.07 |



