2과목에서는 1과목에서 배운 내용을 바탕으로 데이터 결측치 및 이상치를 처리하고 분류모델을 적용해서 정확도 값을 산출해보자
https://www.kaggle.com/datasets/shashwatwork/web-page-phishing-detection-dataset
Web page Phishing Detection Dataset
Detect Phishing in Web Pages
www.kaggle.com
참고할 데이터 셋은 1과목과 동일하게 피싱 데이터 셋을 활용할 예정이다
import 문
import pandas as pd
import numpy as np
=> 1과목에서도 나오는 내용이니까 꼭 암기하자
데이터 로드 및 필요한 데이터만 추출
깔끔한 데이터면 모를까 내가 지금 사용하는 데이터는 행이 많다
피싱 url을 고르는 선택지인데 의미 없는 변수들이 많아 중요하다고 생각하는 특정 변수들만 활용해서
분석을 진행할 예정이다
# 데이터 로드
df = pd.read_csv('dataset_phishing.csv')
# 필요한 열만 선택하여 새로운 데이터프레임 생성
df = df[['status', 'length_url', 'ip', 'nb_dots', 'nb_hyphens', 'nb_at', 'nb_qm', 'nb_and',
'nb_or', 'nb_eq', 'nb_underscore', 'nb_tilde', 'nb_percent', 'nb_slash', 'http_in_path']]
train과 test 데이터 셋 분리
# 특성과 레이블 분리
x = df.drop(columns='status')
y = df['status'].apply(lambda x: 1 if x == 'phishing' else 0) # status 변수를 0과 1로 변환
# 학습용/테스트용 데이터셋 나누기
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2,stratify=y, random_state=42)
위에 사용한 y 종속변수는 문자열이기 때문에 lambda를 활용해서 phishing 데이터 일 경우 1로 아닌 경우는 0으로 바꿈
이후 학습용과 테스트 셋으로 나누는데 stratity를 적용해서 혹시 모를 데이터의 불균형을 해결함
데이터 확인 및 탐색
print("x_train:\n", x_train.head())
print("y_train:\n", y_train.head())
print("y_test:\n", y_test.head())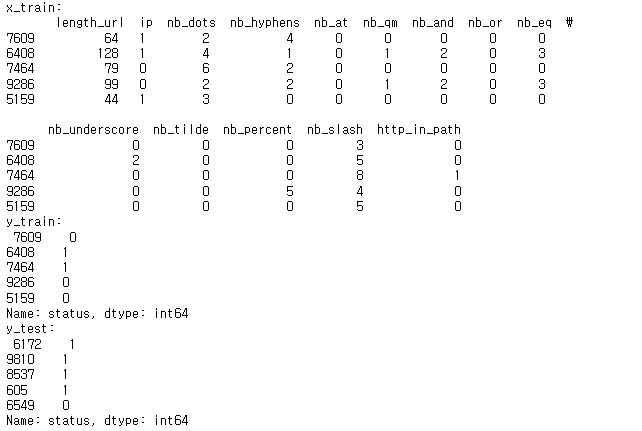
=> head() 함수를 통해 각각 5개의 행의 출력 결과 확인 가능
# 데이터프레임으로 변환
x_test = pd.DataFrame(x_test)
x_train = pd.DataFrame(x_train)
y_train = pd.DataFrame(y_train)
=> 행열 파악을 좀 더 쉽게 변경
x_test.reset_index()
y_train.columns = ['target'] #Y값 열을 target으로 설정
#df라고 하면 이전 데이터프레임의 변수 불러옴
print(y_train.value_counts())
=> 종속 변수 y값인 status를 헷갈리지 않게 target이라는 변수로 칼럼 변경
# 데이터 설명
print(df.info()) # 데이터의 기본 정보(열 이름, 데이터 타입, 누락값 등) 출력
print(df.describe()) # 데이터의 기초 통계 요약 출력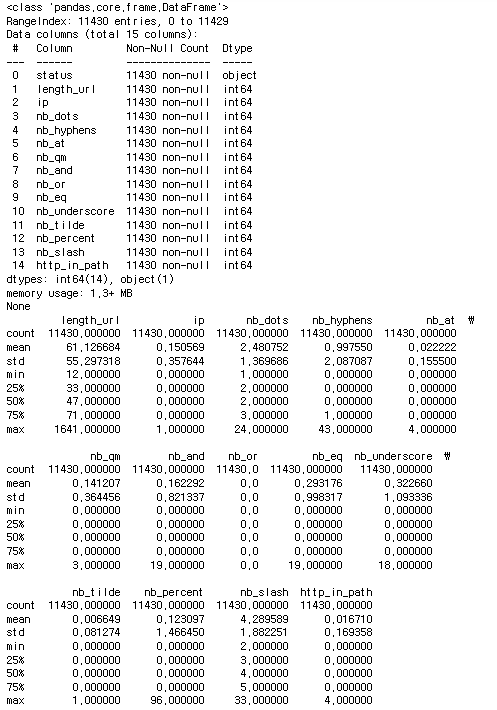
=> info()로 null값이 있는지 확인하고 dtype을 확인함
=> describe() 로 데이터의 기초 통계를 확인하는데 x_train 과 x_test의 전체적인 평균 등이 비슷한지 확인
만약 비슷하지 않다면 이상치가 있다는 것을 짐작 할 수 있음
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)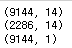
=>shape 함수로 각각의 행과 열의 개수를 파악
#y_train 데이터 보기
print(y_train.head())
print(y_train.value_counts())
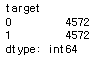
=> 종속변수의 분포가 반반씩 이라는 것을 확인 가능
데이터 결측치 이상치 확인 후 처리하기
#결측치 확인 -> 꼭 알기!!
print(x_train.isnull().sum())
print(x_test.isnull().sum())
print(y_train.isnull().sum())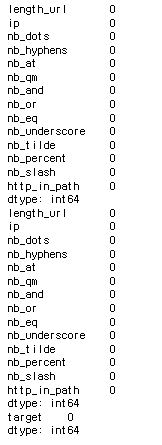
=>isnull().sum()으로 결측치 개수 확인
다행히 해당 데이터에 결측치는 존재하지 않음
train 데이터와 val데이터 분리
from sklearn.model_selection import train_test_split
x_train, x_val, y_train, y_val = train_test_split(x_train,
y_train['target'],
test_size=0.2,
stratify= y_train['target'],
random_state=2023
)y_test를 예측하기 위해서 train 데이터 셋의 분리 진행
print(x_train.shape)
print(x_val.shape)
print(y_train.shape)
print(y_val.shape)
=> train과 val의 행열 파악
모델링 및 성능평가
#랜덤포레스트 모델 사용
from sklearn.ensemble import RandomForestClassifier #대소문자 구분하기
model = RandomForestClassifier()
model.fit(x_train, y_train) #모델에는 train데이터를 넣어서 학습시켜야함
=> 랜덤포레스트 모델이 분류와 회귀 모델 둘다 가능한 모델임
#모델을 통해서 테스트 데이터 y값 예측
y_pred = model.predict(x_val)x_val을 넣어서 y_pred를 만들고
이후 y_pred 예측값과 y_val 실제값을 비교해 성능평가를 진행함
#모델 성능평가(정확도 f1score, 민감도, 특이도 등 )
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, recall_score, precision_score
acc = accuracy_score(y_val,y_pred)
f1 = f1_score(y_val, y_pred, average ='macro')대표적으로 모델을 성능하는 평가인 정확도, f1-score, 민감도, 특이도 등을 활용해서 평가함
#정확도
print(acc)
#micro f1 score
print(f1)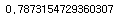
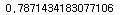
=> 정확도가,,,애매함
최종 답 y_test 예측값 제출
위에 성능평가에 이어서 x_test를 넣어서 y_test 예측
예측값 구하는 방식은 두가지로 나뉨
1. 특정 클래스로 분류 할 경우
2. 특정 클래스로 분류 될 확률을 구할 경우
#1. 특정 클래스로 분류 할 경우(predict)
y_result = model.predict(x_test)
print(y_result[:5])
#2. 특정 클래스로 분류될 확률을 구할 경우 (predict_proba)
y_result_prob = model.predict_proba(x_test)
print(y_result_prob[:5])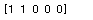
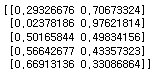
=> 위에 다룬 데이터는 1과 0으로 나뉘는 이진분류라서 클래스도 1 또는 0으로 나뉘는 걸 확인 가능함
'자격증 > 빅데이터분석기사' 카테고리의 다른 글
| 빅데이터분석기사 실기 1과목 데이터 표준화, min-max scaling,데이터 합치기 (0) | 2024.11.15 |
|---|---|
| 빅데이터분석기사 실기 1과목 실기 데이터 결측치, 이상치, 중복값 처리 (0) | 2024.11.14 |
| 빅데이터분석기사 실기 1과목 groupby, 인덱싱, 열 추가/제거, 필터링, 정렬, np.where(조건문) (0) | 2024.11.13 |
| 빅데이터분석기사 실기 1과목 데이터산포도 분산, 표준편차, iqr, 절댓값 , 최대최소, 합계 (2) | 2024.11.12 |
| 빅데이터분석기사 실기 1과목 head, info, describe, shape, dtypes, astype, 최소값/최대값/최빈값, 변수 개수 구하기 정리 캐글 데이터 활용 (0) | 2024.11.07 |



