데이터 시각화 툴의 대표적인 것 중 하나인 태블로
실제로 기업에서 시각화 툴로도 많이 사용하는 기법이라고 한다
예전에 프로젝트를 하면서 간단하게 공부하긴 했는데 정확한 사용법에 대해선 잘몰라서
이번 기회에 책으로 공부를 진행할 생각이다
태블로 public
태블로에는 다양한 종류가 있다
그중 완전 무료인 태블로를 다운 받아서 데이터 시각화를 진행할 예정이다
https://www.tableau.com/ko-kr/products/public
Tableau Public
Tableau 커뮤니티에서 영감을 얻으십시오. '오늘의 비주얼리제이션'에 등록해 매일 새로운 데이터 스토리텔링 걸작품을 받은 편지함으로 받아보십시오. 오늘 구독하기
www.tableau.com
해당 링크로 들어가면 무료로 시각화를 할 수 있다
https://data.seoul.go.kr/dataList/OA-21276/S/1/datasetView.do
열린데이터광장 메인
데이터분류,데이터검색,데이터활용
data.seoul.go.kr
위에 링크는 우리나라 "서울특별시_전월세가 정보" 이다 해당 자료의 2024년도를 활용해서 데이터를 넣어보고
시각화하는 작업을 진행해볼 예정이다
데이터셋 전처리
태블로는 csv가 아닌 엑셀파일만 가능해서 별도의 파일 저장을 진행했다
근데 데이터 셋이 너무 많아 시간이 오래걸린다,,
보니까 데이터셋이 행만 54만개 ㄷ ㄷ
그래서 일단 중요한 데이터 열과 결측치가 있는 값들은 전부 지우고 시작할 예정이다
#주피터를 활용한 데이터셋 분리
import pandas as pd
# Excel 파일 경로
input_file = '서울특별시_전월세가_2024.xlsx' # 입력 Excel 파일 경로
output_file = '서울특별시_전월세가_2024_new.xlsx' # 출력 Excel 파일 경로
# Excel 파일 읽기
df = pd.read_excel(input_file)
# 실제 열 이름 출력 (디버깅용)
print("2024년 열 이름:", [repr(col) for col in df.columns]) # 열 이름 확인
# 열 이름 수정 (공백 제거)
df.columns = df.columns.str.strip()
# 열 이름 변경 (필요한 경우)
df.rename(columns={
'접수연도': '접수년도',
'전월세 구분': '전월세구분',
'임대면적(㎡)': '임대면적'
}, inplace=True)
# 남기고 싶은 컬럼 리스트
columns_to_keep = [
'접수년도',
'자치구코드',
'자치구명',
'법정동코드',
'법정동명',
'전월세구분',
'보증금(만원)',
'임대료(만원)',
'임대면적',
'건축년도',
'건물용도'
]
# 열 이름이 존재하는지 확인하고 필터링
missing_columns = [col for col in columns_to_keep if col not in df.columns]
if missing_columns:
print(f"다음 열이 데이터프레임에 없습니다: {missing_columns}")
else:
# 원하는 컬럼만 남기기
df_filtered = df[columns_to_keep]
# 결과를 새로운 Excel 파일로 저장
df_filtered.to_excel(output_file, index=False)
print("2024년 특정 컬럼만 남기고 Excel 파일이 저장되었습니다.")총 11개의 열과 435266개의 행을 가진 데이터 셋 파일이 저장되었다
이제는 진짜 태블로에 데이터 파일을 불러와보자
엑셀파일 불러오기

microsoft excel > 파일 선택

이렇게 sheet1에 파일이 떴다
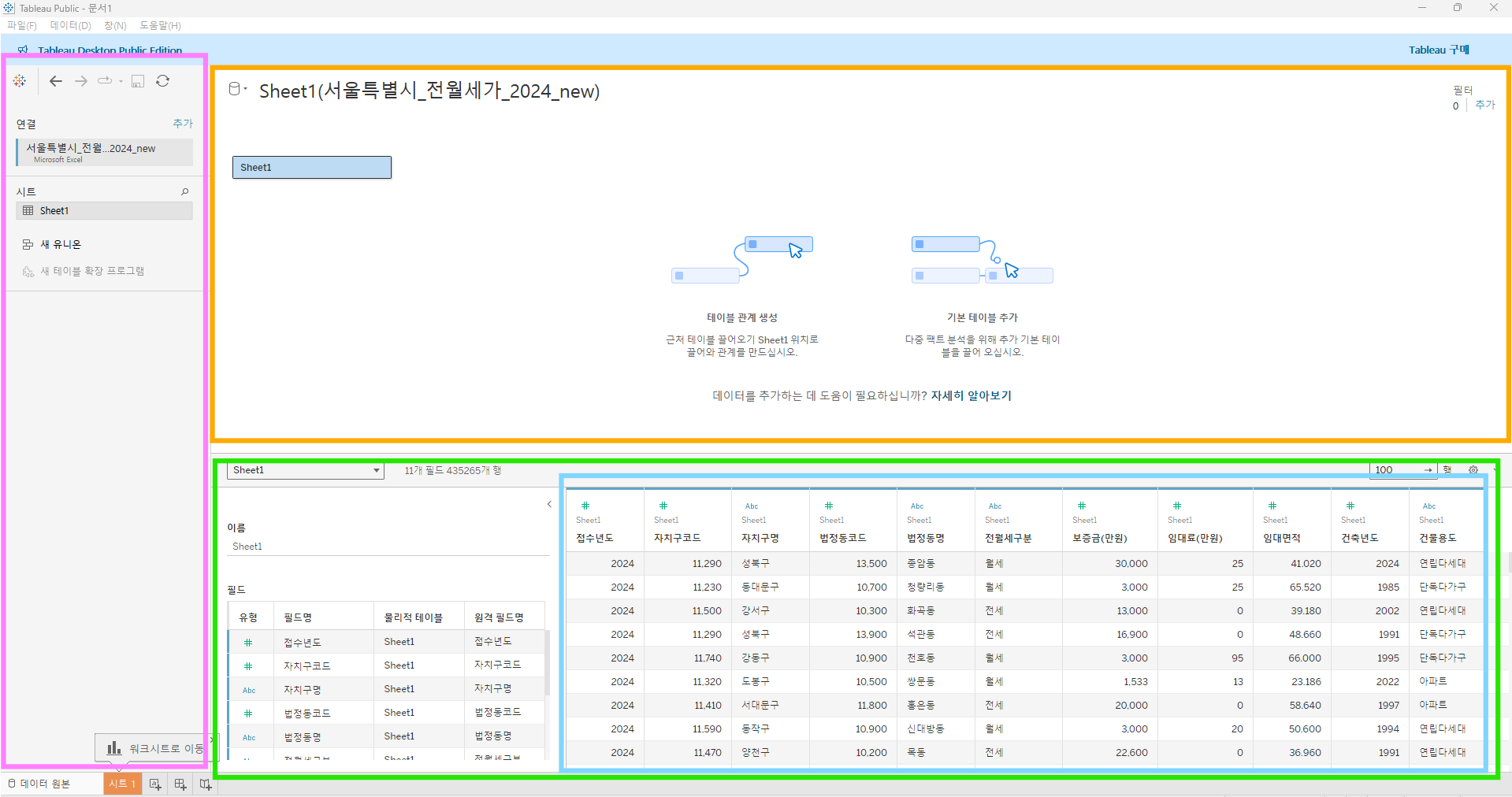
분홍색 : 왼쪽 패널
노란색 : 캔버스 ( 데이터 원본 결합 현황 - 조인 등)
초록색 : 그리드 (데이터 원본 미리보기 영역)
하늘색 : 메타데이터 그리드 ( 데이터 요약본)

위에 노란색 여백 아무곳이나 누르면 태블로 작업 영역에 들어와진다
빨간색 : 사이드 바(데이터 패널과 분석 패널)
하늘색 : 선반(필드를 드래그 하고 데이터를 어떻게 나눌지)
보라색 : 마크(필드를 마크의 여러속성에 드래그 하면 뷰의 세부정보 표시)
노란색 : 뷰(데이터 시각화 표시)

보라색 : 데이터 원본
( 원통하나만 있는 경우 - 라이브 연결 /
원통 두개인 경우 추출로 만들어진 데이터 원본 /
태블로 아이콘은 태블로 서버에 게시된 데이터 원본에 연결 된 경우)
하늘색 : 차원( 데이터의 정성적인 값 )
# : 숫자
ABC : 문자
주황색 : 측정값( 데이터의 정량적인 값 )
오늘은 간단하게 데이터를 불러오고 첫 화면 구성에 대해서 공부했다
다음에는 실제로 데이터를 움직여 새로운 시각화 대시보드를 만들어볼 예정이다
'데이터엔지니어링 > 데이터시각화' 카테고리의 다른 글
| 대시보드 시각화 툴 (1) | 2024.11.21 |
|---|
