분석모형을 마무리로 4과목의 정리가 끝났다
이제 이어서 2과목에 대해서 공부해보자
https://mcode.co.kr/mypage/lecture_view?wm_id=993&lecture_id=8&lecture_sub=41&lecture_num=4
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
2과목은 데이터전처리, 데이터탐색, 통계기법의 이해 세가지가 있다고 한다
순대로 하는것도 상관없지만 비전공자의 경우 통계에 대한 기본적인 내용을 알고 넘어가는게 이후의 공부에 도움된다고 해서
1) 통계기법 -> 2) 데이터탐색 -> 3) 데이터 전처리 순으로 공부할 예정이다
통계기법 이해하기
1. 기술통계와 추론통계
| 기술통계 : 데이터를 정리요약 묘사 | 추론통계 : 모집단의 특성을 추론/검정 |
| 1) 데이터 중심(중심경향도) -평균 -중앙값 -최빈값 2) 데이터 산포 -분산 -표준편차 -사분위범위 -범위 -변동계수 3) 데이터의 퍼진모양 -왜도(비대칭도) -첨도(뾰족한정도) |
1) 추정 -점추정 -구간추정 2) 가설검정 -귀무/대립가설 -제1종, 제2종오류 -유의수준, 유의확률 |
2. 모집단과 모수집단
모집단 : 알고 싶어하는 집단

3. 대표성 : 표본이 모집단을 잘 나타내려면 대표성을 가져야함
1) 표본수의 수 증가
2) 표본추출방법
-단순랜덤추출
-층화추출
-계통추출
-집락추출
표본추출방법
<대표성을 가지기 위한 표본추출 방법>
1. 단순랜덤추출(cluster random sampling)
-무작위로 랜덤 추출하는 방법
-예) 무작위로 10개 뽑기
2. 층화추출 (cluster random sampling)
-각각 그룹별로 일정 비율 뽑기
-예) 생산라인1개에서 5개 생산라인2에서 5개
3. 계통추출 (cluster random sampling)
-일정 간격으로 샘플 뽑기
-예) 생산품 당 5개 당 1개씩 샘플링해 10개 샘플링
4. 집락추출(cluster random sampling)
-특정 집락을 선택해 전수를 사용하거나 일부 사용
-예) 생산 1라인에서만 10개 샘플
**층화추룰과 집락추출의 차이
층화추출은 집단 내 동질적, 집단 간 이질적
집락추출은 집단 내 이질적, 집단 간 동질적
확률표본과 비확률 표본
| 확률 표본 | 비확률 표본 |
| -단순랜덤표본 -층화추출 -계통추출 -집락추출 |
-편의 표본 추출 -유의 표본 추출 -지원자 표본 추출 -눈덩이 표본 추출 -할당 표본 추출 |
**비확률 표본에 이런 종류가 있다는 정도만 알고 가기
기술통계 1) 데이터 중심
1. (산술)평군 mean
-모든 자료를 더해서 자료 수로 나눈 값
-극단값의 영향 많이 받음
2. 중앙값 meadian
-오름 차순으로 나열된 된 데이터의 50%에 해당하는 값
-극단값에 영향을 받지 않음
3. 최빈값 mode
-가장 빈도가 높은 값
-극단값에 영향 안받음
-2개이상 존재 가능
*참고
-기하평균 : 성장률, 증가율, 물가상승률 등
-조화평균 : 평균속력, f1-score = 2 * (정밀도*재현율) / (정밀도+재현율)
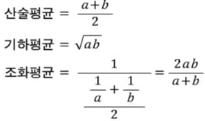
기술통계 2) 데이터 산포
1. 분산과 표준편차
1) 편차: 개별값 - 평균값
2) 분산: 편차의 제곱을 모두 더해 평균을 낸 값
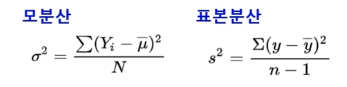
3) 표준편차: 분산에 제곱근을 취한 값
(원래 단위에 맞게 전환 된 값)
2. 사분위수(IQR)
-Q3-Q1
Q1 : 1사분위수(25%)
Q2 : 2사분위수(75%)
3. 범위
최댓값 - 최소값
4. 변동계수(CV) ->크기가 다른 값으 비교할 때 사용
표준편차/평균
기술통계 3) 데이터 퍼진 모양
1. 왜도(비대칭도) = Skewness
* 왜도 부호 : 평균-중앙
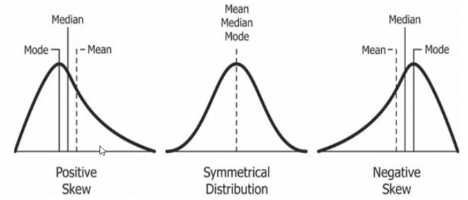
- 평균은 값의 영향을 많이 받음 -> 즉, 값이 커지는 쪽에 mean이 위치
- 최빈값, 중앙값, 평균값의 위치를 물어보는 문제 출제
2. 첨도(뾰족한 정도) = kurtosis
* 첨도값이 높을 수록 뽀죡함
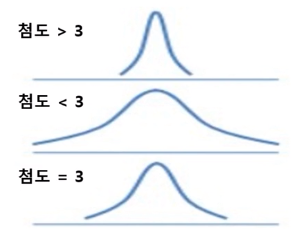
추가로 정규분포는 첨도=3, 왜도=0
데이터 종류
[무조건 암기]
| 이산형(범주형) -> 지도학습 분류 |
명목척도 | 단순 구분하는 척도, 순서와 차이가 없음 예) 남녀, 정상/비정상 |
| 순서척도 | 순서를 말할 수 있음 예) 상중하 |
|
| 연속형 ->지도학습 회귀 |
구간척도 | 원점이 없는 데이터 예) 온도, 지수 |
| 비율척도 | 원점이 있는 데이터 예) 키, 몸무게 등 |
*비교하는 문제도 많이 나오고 실제로 공부할 때 많이 사용하는 개념이니 알아두기



