3과목을 마무리하고 이번 시간부터 4과목에 대해 정리해보도록 하겠습니다
이번 강의도 역시 메타코드에서 참고해서 공부했습니다
https://mcode.co.kr/mypage/lecture_view?wm_id=993&lecture_id=6&lecture_sub=38&lecture_num=3
메타코드M
빅데이터 , AI 강의 플랫폼 & IT 현직자 모임 플랫폼ㅣ메타코드 커뮤니티 일원이 되시기 바랍니다.
mcode.co.kr
이전 3과목의 연관분석에 대한 개념 정리는 아래 링크 참고하세요!
[빅데이터분석기사] 필기 3과목 메타코드 강의 | #12 다변량분석/시계열 분석, 비모수 통계 개념
이번 강의에서는 비지도학습 군집학습과 연관학습에 이어서 [빅데이터분석기사] 필기 3과목 메타코드 강의 | #11 연관분석 개념 정리 및 문제 풀이 저번시간의 비지도학습 중 하나인 군집 분석에
toonovel.tistory.com
분류모형평가 - 회귀성능
4과목에서는 3과목에서 나온 모형을 바탕으로 평가를 한다
먼저 지도학습 중 회귀에서 성능 평가를 방법!!
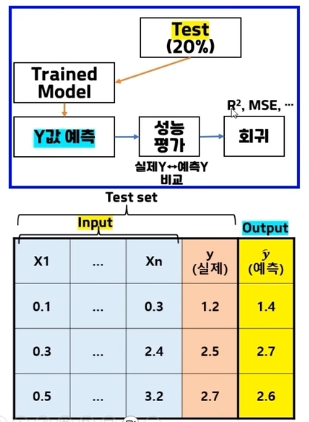
아래 사진에 나온 input부분에서 test set에 적용된 독립변수들이 나오고
이후 output에 y값 예측을 적용해ㅡ성능평가에서 실제y와 예측y를 비교한다
대표적인 성능 측정 방법에는 총 5가지가 있다

실제값과 예측값의 차이를 계산해서 성능을 측정하는 것으로
각 식을 보여주고 어떤 식인지 맞추는 문제 유형들이 나오니까 공부하도록 하자
*결정계수 : 총변동중에 회귀식이 설명 가능한 비율 = SSR/SST = 1- (SSE/SST)
-SSR : 회귀식에 의해 설명 되는 변동
-SSE : 회귀식으로 설명 불가능한 변동
-SST : 총 변동(SSR+SSE)
분류모형평가 - 분류성능
이번에는 분류를 기준으로 지표를 나타내는 방식을 알아보자
앞서 본 회귀 성능과 다르게

분류 형태로 나누는거기 때문에 실제값과 예측값이 0 또는 1로 나오는데
이때 값이 (0,0) (1,0) (0,1) (1,1)로 총 네가지가 나온다

이걸 혼동행렬이라고 하는데
리를 활용해 각 비율을 계산할 수 있다
**주의**
실제와 예측의 위치는 다를 수 있으니 꼭 확인!
예측기준으로 4가지의 위치 항목을 표시하자
1. 정확도 : 전체 중에 잘 분류한 비율
(TP + TN) / (TP + TN + FN + FP)
2. 민감도 = 재현율 : 실제 POSITIVE 중에 잘 분류한 비율TP / (TP + FN)
3. 특이도 : 실제 NEGATIVE 중에 잘 분류한 비율TN / (FP + TN)
4. 정밀도 : 예측 POSTIVE 중에 잘 분류한 비율TP / (TP + NP)
5. F1-SCORE : 2*정밀도*재현율 / (정밀도+재현율) => 데이터 불균형이 있을 경우에는 다른 지표도 필요함
=> 암기하기 보다 이해를 통해서 계산방법을 익히자



